
Why You Can’t Ignore Change Data Capture in Event-Driven Architectures
Sharpen your skills before AI makes you obsolete (just kidding… maybe)

I know, I'm repeating myself lately, but I reaffirm myself on the idea that a Software Engineer or Tech Lead must raise the bar and enhance their technical skills in modern architectures.
That’s why, in today's issue, I will go deeper into one of the patterns that saved my day plenty of times when implementing systems: The Change Data Capture pattern.
You will learn:
What the Change Data Capture is.
How it works.
Differences with Domain Events.
The main use cases, so you know when to apply this pattern.
And some code, just to not make it too boring.
☝🏼Let’s start with a straight and clear definition:
Change Data Capture (CDC) is a design pattern for monitoring and recording row-level changes (INSERT, UPDATE, DELETE) in a database and turning them into a stream of events.
In an event-driven architecture (EDA), CDC lets systems react to data changes as they happen. Instead of applications writing data directly to other services, CDC bridges the database and the event bus:
👉🏼 It emits a change event whenever a database row is modified.
This ensures downstream services see every change in the original order and can update their own state accordingly.
For example, when a user’s profile row is updated in Service A’s DB, CDC can publish a CustomerUpdated event so Service B can refresh its cache or projection without querying Service A’s database directly.
CDC is useful for replicating data, keeping read-models in sync, updating search indexes or caches, and feeding analytics, all with low latency and decoupled manner.
☝🏼 An important difference: Unlike a one-time ETL batch, a CDC pipeline continuously streams changes as real-time events. This makes the pattern indispensable in EDA: it continuously pushes changes (often via Kafka or other message brokers) instead of relying on periodic polls.
⚙️ How CDC Works in Event-Driven Systems
☝🏼 CDC implementations typically fall into three categories:
Query-based.
Log-based.
Outbox pattern.
In the query-based (polling) approach, a connector periodically runs a query (e.g. based on a timestamp or incrementing ID) to find new or changed rows, or just bulk the current state of the data.
This approach works especially if you bulk everything, even though it may introduce latency (since changes are only caught on each poll).
In contrast, log-based CDC reads the database’s transaction log (e.g. MySQL binlog, PostgreSQL WAL) in real time. Because every write is recorded in the log, a log-based CDC connector never misses a change and adds very low latency. In practice, open-source tools like Debezium hook into the database log (or logical replication stream) and publish each table’s changes to Kafka topics.
Outbox pattern for CDC is the strategy I used the most. In this scenario, the database is “replicated” into a broker, for example, a Kafka topic. From there, you can have a process that, in a scheduled manner, consumes the full topic from the beginning and send the data to another topic.
Whether the strategy is, the basic flow is:
The CDC tool detects a row change,
Packages it as a “change event”,
And sends it into a message bus.
From here, downstream microservices subscribe to these topics. Each change event typically includes the operation type (CREATE, UPDATE, DELETE) and the row data before and after the change.

For example, after a UPDATE users SQL, a CDC event might contain the old user record and the new values. This ensures all interested services see the exact change and can update their own models or trigger further processing.
A CDC pipeline often looks like this (Debezium/Kafka example):
Debezium connector connects to the source database and reads its log; whenever a row changes, Debezium writes a JSON/Avro event to a Kafka topic named after the table.
Consumers then read the topic to update caches, search indexes, read-model databases, or other services.
Now, I want to address, at a high level, what is different in CDC with respect to Domain Events. If you are interested in knowing more about the differences between both CDC and Domain events, you can read a full article about this here 👇🏻

🧐 CDC vs. Domain (Business) Events
☝🏼 It’s important to distinguish CDC events from domain/integration events.
👉🏼 CDC events are technical data-change events, not explicit business intentions. That’s the main point.
They simply reflect “what changed” in the data store, without semantic context. You can think about this like:
A technical reflection of the database change with no explicit business context.
For instance, changing a user’s email would generate a low-level User record update event, not a UserEmailChanged business event. CDC is great for keeping data models in sync, but by itself, it doesn’t convey why the change happened.
Architects warn that CDC events should usually be used for internal syncing or read-model updates, not as public integration contracts between services.
📝 Common Use Cases for CDC in EDA
CDC is a versatile pattern in event-driven systems.
☝🏼 Common use cases include:
Real-time data replication: Updating search indexes, caches, or read-model databases whenever the source data changes.
Materialized views / CQRS: Many microservices maintain local read-models or projections. Using CDC, a service can subscribe to changes in another service’s DB and update its own view.
Inter-service synchronization: Services in a distributed system often need consistent data. CDC lets Service A emit changes from its database, and Service B (or many) consume them to stay synchronized without tightly coupling to A’s DB.
Audit and compliance: Because CDC captures every change, it naturally provides an append-only log of all database activity. You can keep this log in Kafka or another store to audit who changed what and when. This is especially useful for traceability and rollback.
In all these cases, CDC treats database changes as events to propagate asynchronously. The messaging layer (often Kafka) decouples producers and consumers.
I’ve put a lot of theory here, so let me share with you some code to exemplify the CDC pattern.
👩🏻💻 CDC Events in Java
A CDC-generated event typically contains the data before and after a change, plus an operation type. For illustration, consider a simple Customer record and the corresponding change event:

Suppose a user updates their email. The database row for that user changes, so CDC emits an update event:

In practice, it produces a JSON (or Avro) message with a similar structure. For example, the JSON payload might look like:
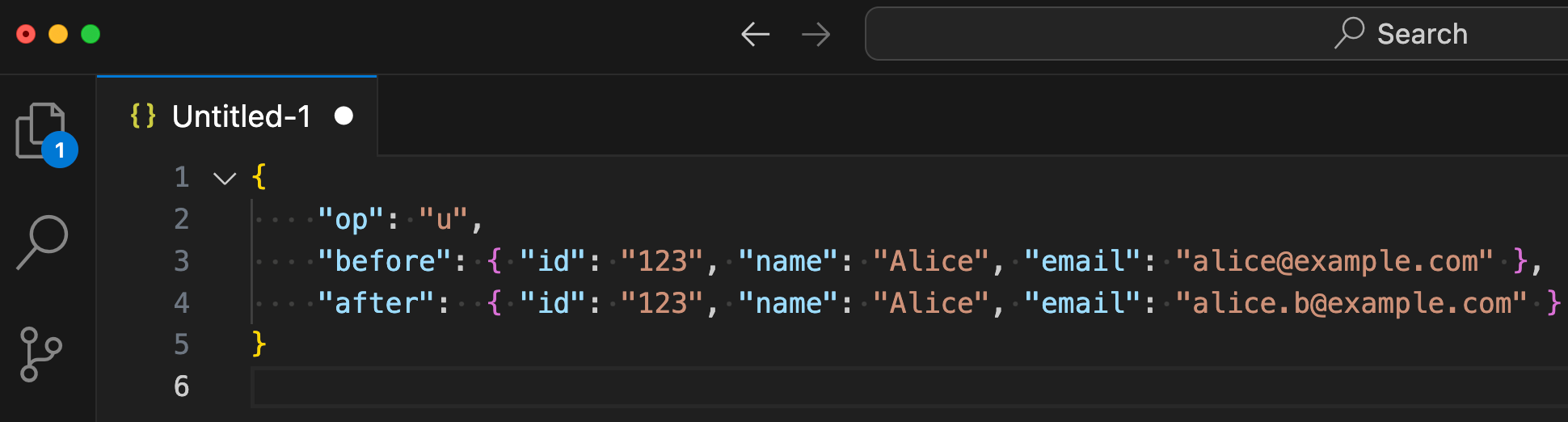
Consumers can deserialize these events into Java objects.
How does it look to you? Let’s wrap up for today with some takeaways.
✨ Takeaways
These are the main ideas I want you to keep after you read this email.
CDC = Data Change Events: CDC is a pattern for capturing database row changes and emitting them as events. It tracks inserts, updates, and deletes, not business logic.
Event-Driven Use: In EDA, CDC bridges legacy or monolithic data stores to event streams. It ensures all systems see the same data changes in real time.
CDC implementation: I personally prefer the Outbox pattern, since I find it more decoupled and not dependent on the storage vendor to have the feature to publish events, but there are others.
Not a Business Event: CDC events carry raw data changes. They lack explicit business semantics. Use them for internal syncing rather than public domain events.
Common Uses: CDC is widely used for cache/search index updates, materialized view maintenance (CQRS), and keeping microservices in sync.
Hope you like this email.
Is there any pending question you want me to address? Anything else you want me to go deeper? Reply to this email or send me a new one. I answer all emails from my readers!
We are more than ✨1321 Optimist Engineers✨!! 🚀
Thanks for your support and feedback, really appreciate it!
You’re the best! 🖖🏼
𝘐𝘧 𝘺𝘰𝘶 𝘦𝘯𝘫𝘰𝘺𝘦𝘥 𝘵𝘩𝘪𝘴 𝘱𝘰𝘴𝘵, 𝘵𝘩𝘦𝘯 𝘤𝘭𝘪𝘤𝘬 𝘵𝘩𝘦 💜. 𝘐𝘵 𝘩𝘦𝘭𝘱𝘴!
𝘐𝘧 𝘺𝘰𝘶 𝘬𝘯𝘰𝘸 𝘴𝘰𝘮𝘦𝘰𝘯𝘦 𝘦𝘭𝘴𝘦 𝘸𝘪𝘭𝘭 𝘣𝘦𝘯𝘦𝘧𝘪𝘵 𝘧𝘳𝘰𝘮 𝘵𝘩𝘪𝘴, ♻️ 𝘴𝘩𝘢𝘳𝘦 𝘵𝘩𝘪𝘴 𝘱𝘰𝘴𝘵.

Nice read, thank you : )